Our main source code management tool at my employer is SVN. However, in the last year, distributed version control systems have become popular.
Especially GIT, which has been developed by the linux kernel developers has some momentum. Furthermore it has a very nice integration into SVN, so that you can use GIT as an interface to a remote subversion repository. In this post, I will show a little bit how I currently use GIT to interface with different branches of the blueprint and training project.
Distributed Version Control Systems
Subversion is a central source control management systems. This means, that there is only one repository where you commit your changesets to. In contrast, on your local machine, you just have a working copy of that repository. Meaning you have the files from a particular branch in a particular revision on your local machine.
In a distributed version control system, everyone has a complete repository. So you have all the code, in all branches and all revisions on your local computer. To share code, you can now syncronize with other repositories over the internet/intranet, but as well locally or via a usb drive.
You can find a more extensive explaination with really nice graphics here.
Why do you want to use GIT?
This sounds very nice. But why should I use it? I will give you some reasons why I use it currently.
To give you some background: I currently work in a department, which supports other developers working with an company internal framework. So we have a project, which is called PetClinic. This PetClinic is used, in different states, as QA project, as training project, as experiment project and as blueprint project.
Private Branches
In the PetClinic we are trying out the latest features from our framework. As we try those on the development versions of the framework, we naturally run into bugs and might therefore break somethings - which would hinder my collegues work, if I check it into subversion, before the bugs I report get fixed.
For this, GIT enables me to create a private branch. This branch and all the commits to it only lives on my machine. When the bugs are fixed, I can check in everything - but still have a nice history.
Easy Merging
Merging in SVN is a pain. Especially when you look at our situation. We have a branch for the current snapshot blueprint, a branch ‘exercises’ where we have the final solutions of all exercises and finally a branch ‘starter’ which is the base project for our training where the training starts from.
These branches require to be synchronized often, with a very fine grained, selective level. It is very often the case, that I want to merge a few revisions from ‘exercises’ back to ‘starter’. This happens as well, when in training I discover something I want to have in ‘exercise’ and/or in ‘starter’ for the next training. Or if some new feature from the blueprint branch needs to be ported to one of the training branches.
GIT helps me here with a sophisticated merging mechanism. Furthermore I can use git cherry-pick to select one specific changeset I want to have in a branch.
Changing History
Especially for Training, I want, that all my commits are complete and make sense. So someone who looks into my history, should have a step by step description what I did.
Unfortunatly I don’t get everything right the first time. So I often discover after one or two commits, that one line has been missing in a commit or one particular change should belong to another commit.
GIT gives me the opportunity to do so using git rebase.
Local Commits
When working with SVN, you always need a network connection to your SVN server to commit your changes. So typically when in the airplane above the atlantic, you code and make a monster commit.
Furthermore, when you have a network connection, on every commit you wait a few seconds (or more) before the commit is through with the central server. This takes alot of time, I you are not in the company and maybe on a slow VPN connection.
In GIT you commit locally. Against your machine. No network connection required. Only if you synchronize with the external repository - calling push and pull in GIT terminology - you need a connection to this repository. But in this step, you could synchronize hundred nice, small changesets. And you can do it, after your done - while watching TV or brushing your teeth.
Installation of GIT
GIT has been done by the linux kernel developers. So it has been made for linux. And it has been made for the command-line. On linux, you can easily install the git-core package via the package manager.
On windows, I would recommend using cygwin and install GIT via its package manager - I use it every day and it just works fine. I have installed the packages git, git-svn, gitk and git-gui.
You can install GIT on Windows. There is a TortoiseGit on the internet. I have no idea how the quality is now, but one or two years ago I had some problems using it.
For this blog, I’ll show you the stuff on the command line, as real developers use the command-line ;-)
Checkout the PetClinic
Setting up the GIT Repository
So, first lets setup a petclinic project connected to our trunk blueprint:
1 2 3 4 5 6 | |
This will lead to the following message
1
| |
This initializes the repository with telling the GIT-SVN tool, where it can find trunk (which is essentially just a branch for GIT), where it can find the other branches and where it can find the tags.
The star * in the branches tells GIT, that at this place it should take the folder name as name of the branch. So the folder name branches/QA/2.11.1.x/petclinic will be the branch 2.11.1.x for GIT. For the tags it automatically assumes the name at the end, because I didn’t specify anything different.
The GIT repository has now been created. It is located in the .git folder. Your working copy is in the normal file system once you selected a current branch.
Fetching the whole SVN history
Ok, now we can fetch the data:
1
| |
This will now fetch the whole history of all the branches in the PetClinic. So take some time. On larger histories it can take a whole night or more. So be aware - but it has only to be done once.
Importing SVNs Ignore Information
In SVN you have properties svn:ignore on folders, to tell the version control system which files it should not consider when commiting to the repository. In GIT there are configuration files called .gitignore in the root of your repository which define which files to be ignored.
For example this .gitignore file excludes .project files and the target folder:
1 2 | |
But I do not want to check this file into want to check in this file into version control - it might confuse the SVN users. There is another option: .git/info/exclude. This file works just the same - but is local to your repository.
I can generate the .git/info/exclude file from the svn:ignore information with the following command:
1
| |
Basic Operations
GitK
So first of all, I want to see how the different tags and branches behave. A nice point to check this is GITK:
1
| |
This will show something like this:
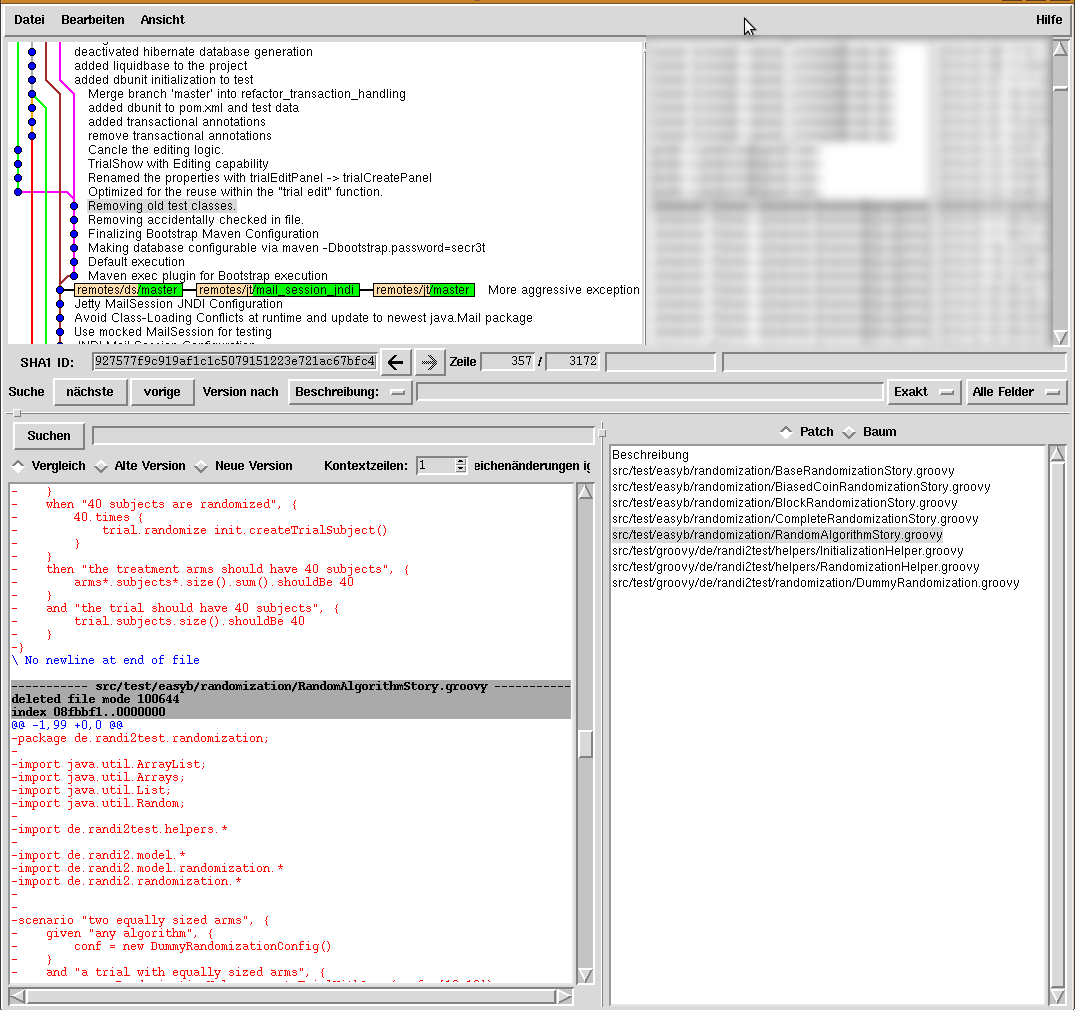
New Branch
Ok. After I know, what I have in my repository I want do do some work. I want to try out the some new featuer in a local branch. So I create a new branch based on the current trunk:
1
| |
So, what does this mean?
git checkout means, that git should “open” the a branch
-b mean, it should create the branch first.
view_compiler_experiment is the name of this new branch
svn/trunk means the new branch should be based on the trunk branch, from the remote repository called trunk
Commit
So now, I’m in this branch - and I made some changes to some files. Now I want to commit them.
In GIT I have a very fine-grained control over what I want to commit. First I need to stage the changes I want to commit. I can do this by using git add path/to/file. In contrast to SVN, I need to do this on all changes - not only on the files which are actually new.
Then commit my changes locally by doing:
1
| |
I could as well do
1
| |
This would automatically stage all changes in files under version control (so this is like the SVN behaviour).
Push to SVN
So now I have a bunch of commits and want to push them up to SVN. But first I want to get any changesets from SVN. This is done by
1
| |
This will fetch the changesets one by one from the SVN an try to merge them with your branch. In my experience, this does not raise so many merge conflicts as usual - and if it does, they are smaller.
Then I am ready to push my changes into the SVN
1
| |
Outlook
GIT and GIT-SVN have a ton of features. I only use a fraction of them - and from those I only showed a even smaller fractions. There is a Cheatsheet on the GIT page only for GIT-SVN. An the internet is full of other tutorials.
I would really encourage you to use it. Just use the comments, if you need any help with it. I might write a sequel in future.